
A-level Chain Rule and AI?
- Ashish Sharma

- Apr 1
- 2 min read
Yes you read this correctly!
Artificial Intelligence (AI) may feel futuristic, but under the hood it is built on ideas you already know from A‑level Mathematics: functions, gradients, and especially the chain rule.
This article uses the diagram below to show how a simple neural network works, and why the chain rule is the engine that allows machines to learn.

1. What You’re Looking At: A Simple Neural Network
The image shows a tiny neural network with:
Inputs: three numbers x1,x2,x3
A hidden layer: collects them into a single value
An activation function: turns that value into a meaningful signal
An output: the network’s prediction
Loss: a measure of how wrong it was
Backpropagation: the method the network uses to learn from its mistake
This structure is the basic blueprint of modern AI.
2. Step-by-Step Explanation Using the Diagram
Step 1 — Inputs

The values x1,x2,x3 could represent anything:
size of a house
difficulty of a question
brightness of a pixel
They are simply numbers fed into the model.
Step 2 — Weighted Sum (Hidden Layer)

Each input has a weight:
z=w1x1+w2x2+w3x3+b
This is just a linear combination, exactly like the vectors and straight-line models you know from Maths.
The network starts with random wi so its predictions are terrible at first.
Step 3 — Activation Function
The hidden layer output becomes: h(z)

Common choices are:
sigmoid
ReLU
tanh
Activations let networks model nonlinear behaviour — that’s why AI can recognise speech, images, and complex patterns.
Step 4 — Output and Loss
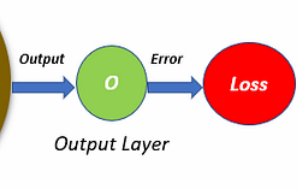
The network produces a prediction O. We compare it to the correct answer, producing a loss (error).
This number tells us how wrong the network is.
3. So Where Does the Chain Rule Come In?
To learn, the network needs to adjust each weight wi, but first it must answer:
How much did each weight contribute to the error?
This is where the chain rule becomes essential.
The Functions Are Nested
Consider the dependence:
L→O→h(z)→w
So L is a function of O, which is a function of h, which is a function of the weights.

A perfect setup for the chain rule.
Backpropagation = applying chain rule repeatedly
From the diagram, the gradient of the loss with respect to a weight is:
This tells the network how each weight affected the final error.
Then we update the weight:

This tiny formula is the reason AI learns.
4. Why This Should Excite A‑Level Students
If you understand:
composite functions
derivatives
chain rule
…then you understand the central idea behind modern machine learning.
Neural networks are not mysterious. They are just lots of functions composed together, trained using the chain rule that you already know.
It’s great to see the applications of the curriculum beyond the classroom!



Comments